どうやらイマノ君はAtCoderというプログラミングコンテストに参加しているみたいです。
その解説にあった座標圧縮がわからないとのこと。
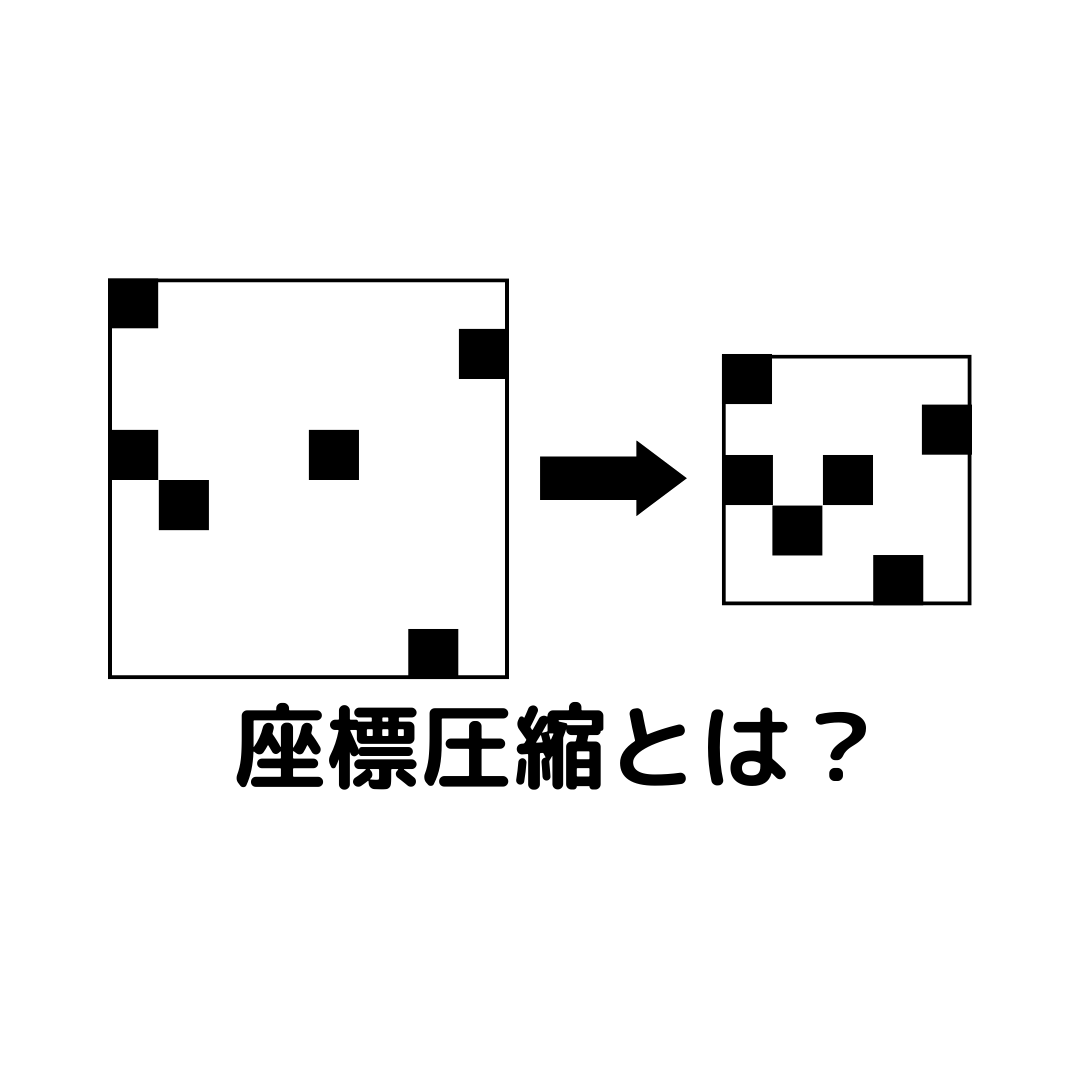
座標圧縮とはいらない部分を切り落とすこと
ユウ兄!最近 AtCoder 始めたんだけど、わからないことばっかりで困ってる!助けて!
お!新しいことにチャレンジするのは素晴らしいですね。
どこがわからないんですか?
解説に 座標圧縮 って書いてあるんだけどこれがよくわからないんだ…
それでは今回は座標圧縮について説明しましょうか!
座標圧縮って何?
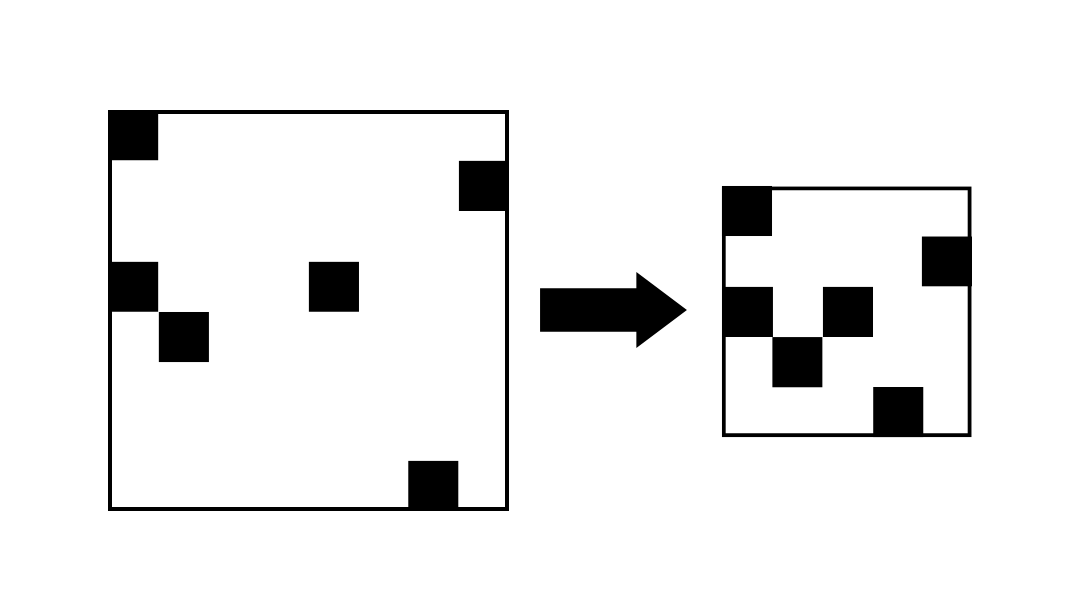
早速ですが、座標圧縮というのは不要な部分を切り落とすことで必要な情報の処理を早くすることです。
いらない部分だけを切り落とすんだね!
そうです!
無駄な部分がなくなるため、探索などを行う際に高速化が可能なんですね。
実際の問題を解いてみる
ABC213-C を解いてたからこれの解説がいい!
わかりました。それではその問題を使いましょう。
座標圧縮ではある数列Aに対して通常以下の順で処理を行います。
1. Aをソートした数列をBとする
2. Bの重複した値を消す
3. Aの全要素についてBの何番目かを調べる
切り落とすだけじゃダメなの…?
そうなんです。主に座標圧縮は探索するのが目的なので元の数列のどこにあるかが重要なんです。
この手順をそのまま実装すると以下のようなコードになると思います。
今回は Python で実装していますよ。
import numpy
from sys import stdin
_, _, n = map(int, input().split())
row = numpy.empty(n, dtype=int)
col = numpy.empty(n, dtype=int)
for i in range(n):
a, b = map(int, stdin.readline().split())
row[i] = a
col[i] = b
row_sorted = numpy.sort(numpy.unique(row))
col_sorted = numpy.sort(numpy.unique(col))
for i in range(n):
print(numpy.where(row_sorted==row[i])[0][0]+1, numpy.where(col_sorted==col[i])[0][0]+1)あれでもこのコードだと時間かかりすぎみたいだよ…?
そうなんです。
ただ単に手順をなぞるだけだと座標圧縮自体に時間がかかりすぎてしまうんですね。
numpy.sort, numpy.unique と numpy.whereに時間がかかりすぎているところが問題です。
そこで set関数をうまく使って重複を消しつつ、辞書に記録することで時間短縮を図ります。
すると以下の模範解答と同じコードになるはずです。( AtCoderのページにも同じものがあります。 )
H,W,N=map(int,input().split())
X,Y=[],[]
for i in range(N):
x,y=map(int,input().split())
X.append(x)
Y.append(y)
Xdict = {x:i+1 for i,x in enumerate(sorted(list(set(X))))}
Ydict = {y:i+1 for i,y in enumerate(sorted(list(set(Y))))}
for i in range(N):
print(Xdict[X[i]], Ydict[Y[i]])すごくスマートに書けるんだね!
まとめ
座標圧縮というのは不要な部分を切り落とすことで必要な情報の処理を早くすることでした。
数列のコピーをとって、同じものを消す。
その後に元の数列のどこにあるかを対応づけるんだよね!
はいそうです!
その際に Python では set 関数と辞書をうまく使って高速化していましたね。
次からはうまく解けそう!
ユウ兄ありがとう!

コメント